
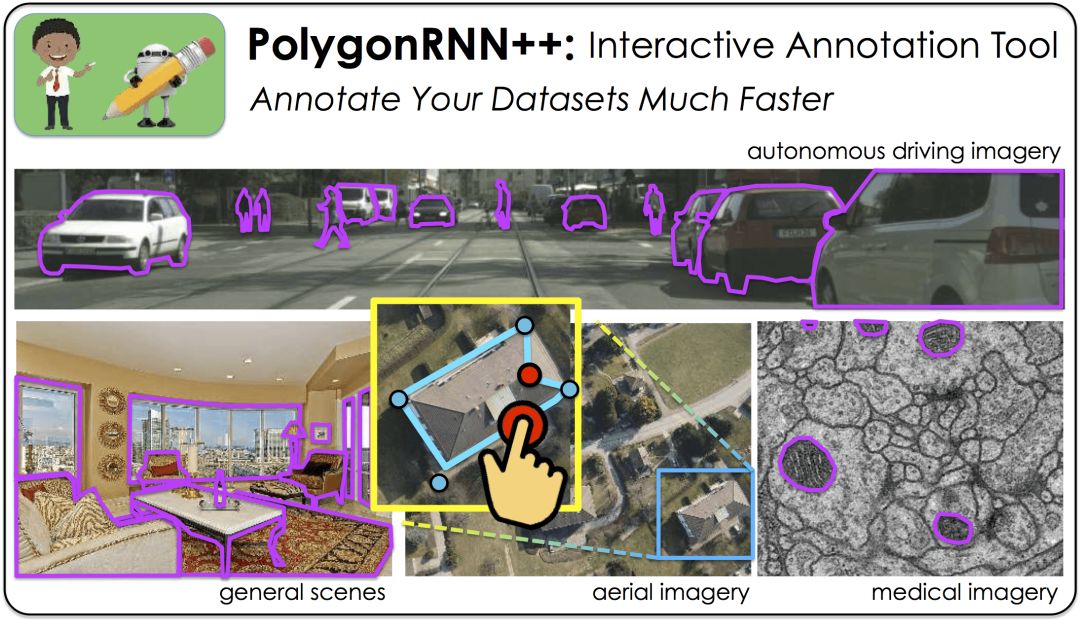
Annotating the object mask in an image is a very time-consuming and labor-intensive work (manually annotating an object takes 20 to 30 seconds on average), but in many computer vision applications (for example, autonomous driving, medical imaging), it is indispensable. The existing automatic labeling software is mostly based on pixels, so it is not smart enough, especially on adjacent objects with close colors. In view of this, LluÃs Castrejón, a researcher at the University of Toronto, et al. proposed the Polygon-RNN labeling system, which was nominated for the best paper in CVPR 2017. Researchers from the University of Toronto David Acuna, Huan Ling, Amlan Kar and others submitted PolygonRNN++, an improved version of Polygon-RNN in CVPR 2018, and recently released the PyTorch implementation.
Polygon-RNN++ architecture
The overall architecture of Polygon-RNN is shown in the figure below:
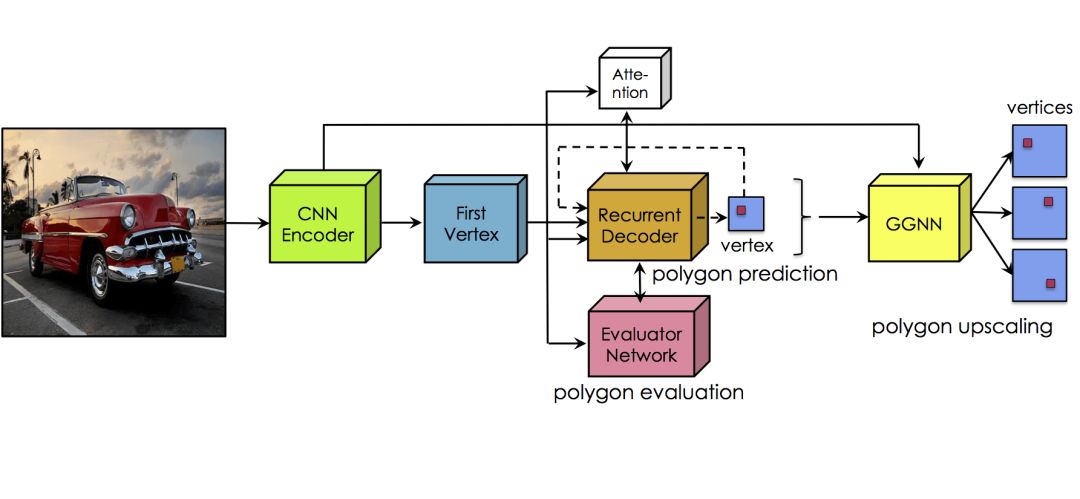
Similar to the previous Polygon-RNN, Polygon-RNN++ uses CNN (Convolutional Neural Network) to extract image features, and then uses RNN (Recurrent Neural Network) to decode polygon vertices. In order to improve the prediction effect of RNN, an attention mechanism is added, and an evaluation network (evaluator network) is used to select the best candidate polygons proposed by RNN. Finally, use Gated Graph Neural Network (GGNN) upsampling to improve the output resolution.
The CNN part draws on the practice of ResNet-50, reduces the stride and introduces dilation, so as to enlarge the input feature map without reducing the receptive field of a single neuron. In addition, skip connections are introduced to capture low-level details such as corners and high-level semantic information at the same time. The rest of the configuration is more conventional, including 3x3 convolution kernel, group normalization (batch normalization), ReLU, maximum pooling (max-pooling) and so on.
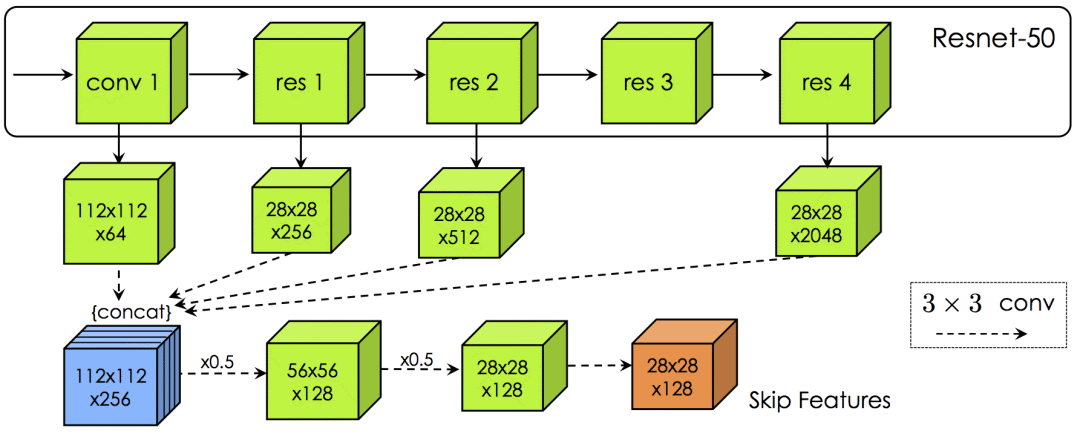
The blue tensor is passed to GNN, and the orange tensor is passed to RNN
In the RNN part, double-layer ConvLTSM (3x3 cores, 64/16 channels, normalization of the application group per time step) is used to preserve spatial information and reduce the number of parameters. The output of the network is a one-hot encoding of (D x D) + 1 elements. The first D x D dimension represents the possible vertex positions (D = 28 in the experiment of the paper), and the last dimension marks the end of the polygon.
In order to improve the performance of the RNN part, an attention mechanism is added. Specifically, at time step t, calculate the weighted feature map:
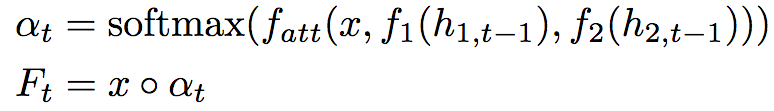
In the above formula, x is the jumping feature tensor, h is the hidden state tensor, f1, f2 use a fully connected layer to map h1, t, h2, t to RDxDx128. Fatt accumulates the sum of inputs and maps it to DxD through a fully connected layer. â—¦ is the Hadamard product. Intuitively speaking, the attention mechanism uses the previous hidden state of the RNN to control a specific position in the image feature map, so that the RNN only focuses on relevant information in the next time step.
In addition, the first vertex needs special processing. Because, given the vertex before the polygon and an implicit direction, the position of the next vertex is always determined, except for the first vertex. Therefore, the researchers added a branch containing two DxD-dimensional network layers, allowing the first layer to predict edges and the second layer to predict vertices. When testing, the first vertex is sampled from the last layer of the branch.
The choice of the first vertex is critical, especially when there is occlusion. The traditional cluster search is based on logarithmic probability, so it is not suitable for Polygon-RNN++ (points on the occlusion boundary generally have a high logarithmic probability during prediction, reducing the chance of it being removed by the cluster search). Therefore, Polygon-RNN++ uses an evaluation network consisting of two 3x3 convolutional layers plus a fully connected layer:
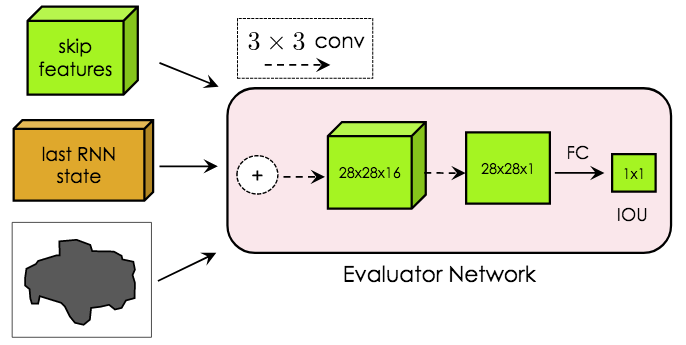
The evaluation network is trained separately, and the mean square error is minimized through training:
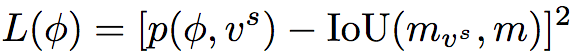
In the above formula, p is the predicted IoU of the network, and mvs and m are the predicted mask and actual mask, respectively.
In the test, based on the first vertex prediction of K before scoring, a polygon is generated through classical cluster search (log probability, beam width is B). Corresponding to the K first vertices, there are a total of K polygons, and then let the evaluation network select the best polygon from them. In the experiment of the paper, K = 5. The reason why the cluster search is first used instead of the evaluation network is that the latter will cause the reasoning time to be too long. Under the setting of B = K = 1, combined with the configuration of the cluster search and evaluation network, a speed of 295ms per object (Titan XP) can be achieved.
When interacting with people, the manual correction will be passed back to the model, allowing the model to re-predict the remaining vertices of the polygon.
As mentioned earlier, for the D x D-dimensional polygon output by the RNN, D is 28. The reason why D is not larger is to avoid exceeding the memory limit. In order to increase the final output resolution, Polygon-RNN++ uses a gated graph neural network for upsampling, treating vertices as nodes in the graph, and adding nodes between adjacent nodes.
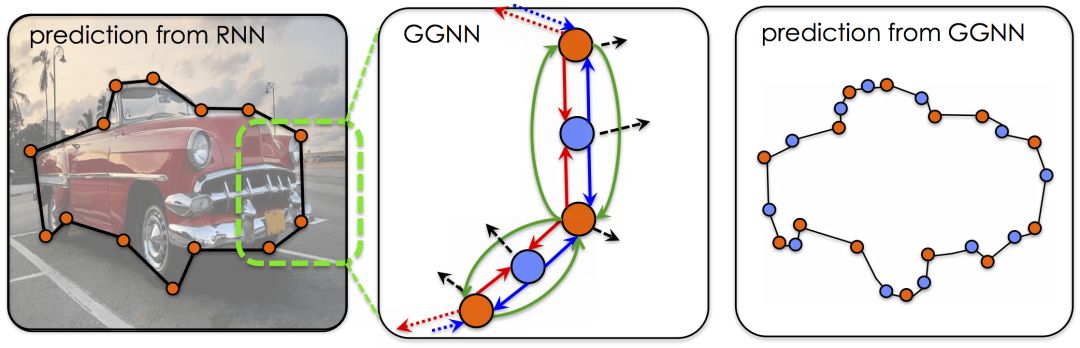
GGNN defines a propagation model that extends RNN to any graph, which can effectively propagate information before generating output on each node.
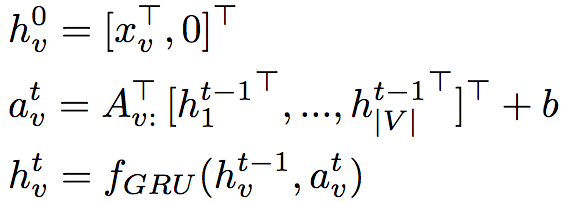
In the above formula, V is the node set of the graph, xv is the initial state of node v, and hvt is the hidden state of node v at time step t. The matrix A ∈ R|V|x2N|V| determines how nodes transmit information to each other, where N represents the number of edge types. In the experiment, a 256-dimensional GRU was used, and the number of propagation steps was T = 5.
The output of node v is defined as:
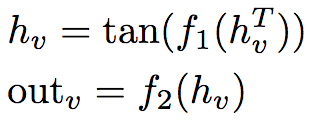
f1 and f2 are MLP (Multilayer Perceptron), and the sizes in the experiment are 256 x 256 and 256 x 15 x 15.
As mentioned earlier, the 112 x 112 x 256 feature map (blue tensor) of the CNN part is passed to GGNN. Around each node v in the graph (after stretching), an S x S block is extracted to obtain a vector xv, which is provided to GGNN. After the propagation process, predict the output of node v, that is, the position on the D'x D'spatial grid. The grid is based on the original position (vx, vy), so the prediction task is actually a relative placement problem, and it can be regarded as a classification problem and trained based on cross-entropy loss. The ground truth of training is the output of the RNN part. If the difference between the nodes in the prediction and the standard answer exceeds the threshold (3 grids in the experiment), it is regarded as an error.
In the experiment, the researchers set S = 1, D'= 112 (researchers found that a larger D'did not improve the results).
Training based on reinforcement learning
Polygon-RNN is based on cross-entropy training. However, training based on cross entropy has two major limitations:
MLE over-punishes the model. For example, although the predicted vertex is not the vertex of the actual polygon, it is on the edge of the actual polygon.
The optimized measures are quite different from the final evaluation measures (such as IoU).
In addition, the actual polygons instead of model predictions are passed into the next time step during the training process, which may introduce bias and lead to a mismatch between training and testing.
In order to alleviate these problems, Polygon-RNN++ only uses MLE training in the initial stage, and then through reinforcement learning training. Because of the use of reinforcement learning, non-differentiable IoU is no longer a problem.
In the context of reinforcement learning, Polygon-RNN++'s RNN decoder can be regarded as a sequence decision agent. The parameter θ of the CNN and RNN architecture defines the strategy pθ for selecting the next vertex vt. After the sequence ends, we get the reward r = IoU(mask(vs, m)). Therefore, the loss function that maximizes the reward is:
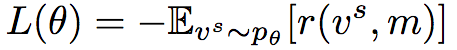
Correspondingly, the gradient of the loss function is:
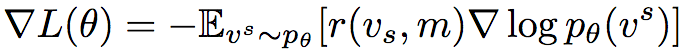
In practice, Monte Carlo sampling is often used to calculate the expected gradient. However, this method has a large variance and is very unstable without proper normalization based on the context. Therefore, Polygon-RNN++ adopts a self-critical method, using the model’s test phase reasoning reward as a baseline:
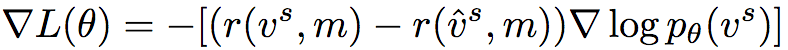
In addition, in order to control the randomness of model exploration, Polygon-RNN++ also introduces a temperature parameter Ï„ in the strategy softmax. In the experiment, Ï„ = 0.6.
test results
The figure below shows the results of Polygon-RNN++ on the Cityscapes dataset. Cityscapes contains 2975/500/1525 training/validation/test images, a total of 8 semantic categories.
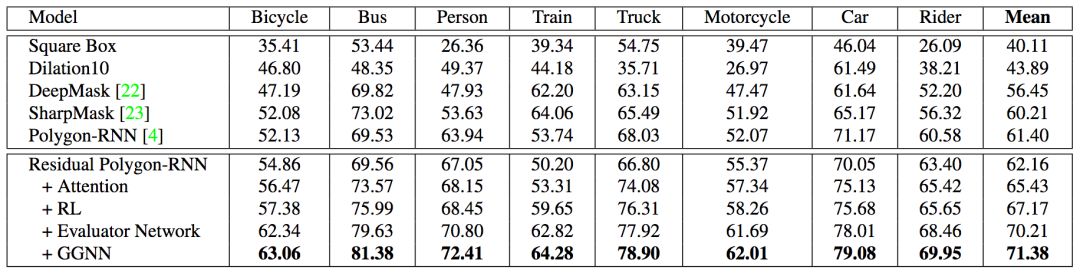
It can be seen that in each category, Polygon-RNN++ surpasses other models, and is higher than the IoU of the best performing model by almost 10%. In fact, Polygon-RNN++ (79.08) defeated humans (78.60) in the classification of cars. The results of the ablation test are also satisfactory.
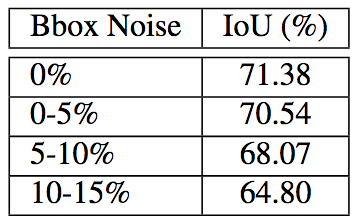
In addition, Polygon-RNN++ is robust to noise:
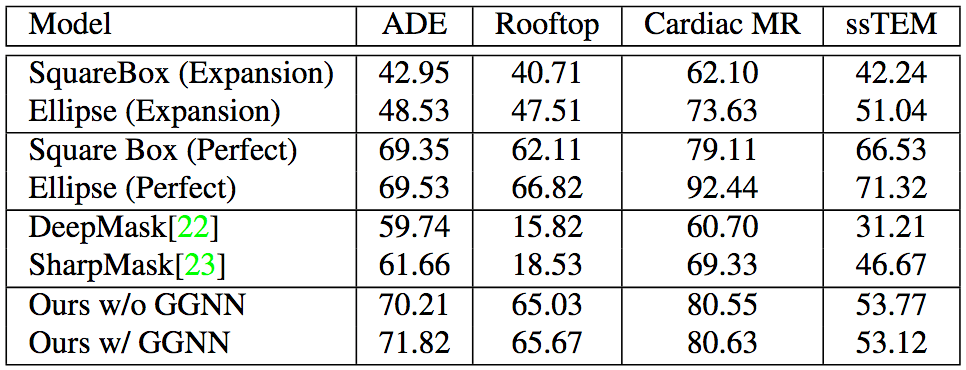
Polygon-RNN++ performs equally well on cross-domain data sets, which shows that Polygon-RNN++ has a good generality.
ZGAR bar 4000 Puffs
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

Disposable Vape, bar 4000puffs, ZGAR bar disposable, Disposable E-cigarette, OEM/ODM disposable vape pen atomizer Device E-cig
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.zgarette.com